

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
在一个有截距项的回归模型估计结果中,已知总的离差平方和SST=49,归直线所能解释的离差平方和SSE=35,那么可知残差平方和SSR等于()。
A.10
B.12
C.18
D.14
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码进入小程序
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码进入小程序
题目内容
(请给出正确答案)
A.10
B.12
C.18
D.14
答案
 更多“在一个有截距项的回归模型估计结果中,已知总的离差平方和SST=49,归直线所能解释的离差平方和SSE=35,那么可知残差平方和SSR等于()。”相关的问题
更多“在一个有截距项的回归模型估计结果中,已知总的离差平方和SST=49,归直线所能解释的离差平方和SSE=35,那么可知残差平方和SSR等于()。”相关的问题
第1题
本题利用401KSUBS.RAW中的数据。
(i) 计算样本中nettfa的平均值、标准差、最小值和最大值。
(ii) 检验假设平均nettfa不会因为401(k) 资格状况而有所不同, 使用双侧对立假设。估计差异的美元数量是多少?
(iii)根据计算机习题C7.9的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e40lk作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv) 在第(iii) 部分估计的模型中, 增加交互项e401k·(age-41) 和e401k·(age-41)2 。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi) 现在, 从模型中去掉交互项, 但定义5个家庭规模虚拟变量:fsize l, j size2,f size 3, f size 4和f size 5。对有5个或5个以上成员的家庭, fsize 5等于1。在第(iii) 部分估计的模型中, 增加家庭规模虚拟变量, 记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii) 现在, 针对模型
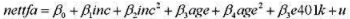
在容许截距不同的情况下, 做5个家庭规模类别的邹至庄检验。约束残差平方和SSR, 从第(vi) 部分得到,因为那里回归假定了相同斜率。无约束残差平方和SSRUR=SSR1+SSR2 +…+SSR5 , 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
第2题
利用MEAP00 O1中的数据回答本题。
(i)使用OLS估计模型
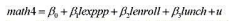
并用通常的格式报告你的结论。在5%的显著性水平上,每个解释变量都是统计显著的吗?
(ii)求出第(i) 部分中回归的拟合值。拟合值的取值范围是多少?它与math4的实际数据取值范围相比如何?
(iii)求出第(i)部分中回归的残差。哪类学校具有最大的(正)残差?对这个残差给予解释。
(iv)在方程中增加所有解释变量的平方项,检验它们的联合显著性。你会把它们放到模型中吗?
(v)回到第(i)部分中的模型,将因变量和每个解释变量都除以各自的样本标准差,并重新进行回归。(除非你还将每个变量分别减去了各自的均值,否则还应该包括一个截距项。)以标准差为单位,哪个解释变量对数学考试通过率具有最大的影响?
第3题
利用DISCRIM.RAW中的数据回答本题。(也可参见第3章计算机练习C8。)
(i)利用OLS估计模型
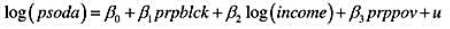
以常用形式报告结果。在5%的显著性水平上,相对一个双侧备择假设,β统计显著异于零吗?在1%的显著性水平上呢?
(ii)log(income)和prppov的相关系数是多少?每个变量都是统计显著的吗?报告双侧P值。
(iii)在第(i)部分的回归中增加变量log(hseval)。解释其系数并报告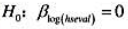 的双侧p值。
的双侧p值。
(iv)在第(ii)部分的回归中,log(income)和prppov的个别统计显著性有何变化?这些变量联合显著吗?(计算一个p值。)你如何解释你的答案?
(v)给定前面的回归结果,在确定一个地区的种族构成是否影响当地快餐价格时,你会报告哪一个结果才最为可靠?
第4题
在模型(9.17)中,证明:如果ai与xi不相关,bi与xi和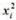 也不相关,这是一个比式(9.19)更弱的假定,那么,普通最小二乘法就能一致地估计α和β。[提示:把方程写成式(9.18)的形式并根据第5章的分析可知, 截距和斜率的OLS估计值一致的充分条件是E(ui)=0和Cov(xi,ui)=0.
也不相关,这是一个比式(9.19)更弱的假定,那么,普通最小二乘法就能一致地估计α和β。[提示:把方程写成式(9.18)的形式并根据第5章的分析可知, 截距和斜率的OLS估计值一致的充分条件是E(ui)=0和Cov(xi,ui)=0.
第5题
本题利用SLEEP75.RAW中的数据。我们要分析的方程为:
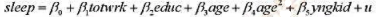
(i)分别针对男性和女性单独估计这个方程,并按照通常形式报告结论。这两个估计方程有什么明显差异吗?
(ii)对男性和女性睡眠方程中的参数是否相等计算邹至庄检验。使用增加male和交互项male totwrk,.male的检验形式,并使用全部观测。该检验相关的df等于多少?在5%的显著性水平上,你应该拒绝这个虚拟假设吗?
(iii)现在,容许男性与女性存在不同截距,判定所有涉及male的交互项是不是联合显著的?
(iV)给定第(ii)部分和第(iii)部分中的结论,你最后将使用什么样的模型?
第6题
用到SMOKE.RAW中的数据。
(i)估计抽烟影响年收入(可能通过因病损失的工作日或生产力效应)的一个模型是
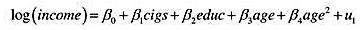
其中,cigs表示平均每天抽烟的数量。你如何解释民?
(ii)为了反映香烟消费可能与收入同时决定,一个香烟需求方程是
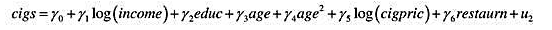
其中,cigpric表示每包香烟的价格(美分),而restaurn表示一个二值变量,并在这个人所定居的州有餐馆抽烟限制时等于1。假定这些变量对个人而言都是外生的,那么你预期y5和y6具有什么样的符号?
(iii)在什么样的条件下第(i)部分的收入方程可识别?
(iv)用OLS估计收入方程并讨论p,的估计值。
(v)估计cigs的约简型。(记住这就要求将cigs对所有外生变量回归。)log(cigprc)和restaurn在约简型中显著吗?
(vi)现在用2SLS估计收入方程。讨论的估计值与OLS估计值的比较。
(vii)你认为香烟价格和餐馆抽烟限制在收入方程中是外生的吗?
第7题
(i)用虚拟变量dem wins来代替式(10.23)中的dem vote,并用通常的格式报告结果。哪些因素影响获胜概率?请用截至1992年的数据。
(ii)有多少个拟合值小于0?有多少个拟合值大于1?
(iii)采用下面的预测规则:如果den wins>0.5, 你就可以预测民主党会获胜:否则, 共和党将获胜。那么,在这20次选举中,这个模型有多少次正确地预测了实际结果?
(iv)代入1996年的解释变量值。预测克林顿赢得这次选举的可能性有多大。事实上,克林顿获胜了,你的预测结果是否与事实相符?
(v)对误差中的AR(1)序列相关,做异方差-稳健1检验。你有何发现?
(vi)求出第(i)部分中估计值的异方差-稳健标准误。t统计量有什么明显的变化吗?
第8题
对(许多美国工人可用的)401(k)养老金计划的出现是否提高了净储蓄,吸引了大量研究兴趣。数据集401KSUBS.RAW包含了有关净金融资产(nettfa)、家庭收入(ic)、是否有资格参与401(k)计划的二值变量(e401k)和其他几个变量的信息。
(i)样本中有资格参与一个401(k)计划的家庭比例是多少?
(ii)估计一个用收入、年龄和性别解释401(k)资格的线性概率模型。包括收入和年龄的二次项,并以通常形式报告结论。
(iii)你认为401(k)资格独立于收入和年龄吗?性别呢?请解释。
(iv)求第(ii)部分中估计的线性概率模型的拟合值。有小于0或大于1的拟合值吗?
(v)利用第(iv)部分中的拟合值e401k1,定义e401k1在e401k≥0.5时取值1,并在2e401k<0.5时取值0。在9275个家庭中,预计有多少家庭有资格参与401(k)计划?
(vi)对于没有资格参加401(k)的5638个家庭,利用预测值e401k1,预测其中有多大比例没有401(k)?对于有资格参加401(k)的3637个家庭,其中有多大比例的家庭有401(k)?(如果你的计量经济软件具有“制表”命令更好。)
(vii)总正确预测比约为64.9%。给定第(vi)部分的答案,你认为这是模型好坏的一个完备描述吗?
(viii)在线性概率模型中增加一个解释变量pira。其他条件不变,若一个家庭有某人拥有个人退休金账户,一个家庭有资格参与401(k)计划的估计概率会提高多少?在10%的显著性水平上,它统计显著异于0吗?
第9题
为因变量。
(i)将log(avgprc)对四个工作日虚拟变量(星期五作为基准)进行回归,其中包含一个线性时间趋势。有价格在一周之内系统变化的证据吗?
(ii)现在,增加变量wave2和wave3,它们度量了过去几天的浪高。这些变量个别显著吗?描述一种机制,使得海面越是风大浪急,鱼价就越高。
(iii)在回归中增加了wave2和wave3后,时间趋势有何变化?接下来会发生什么?
(iv)解释为什么回归中所有的解释变量都被安全地假定为严格外生的。
(v)检验误差中的AR(1)序列相关。
(vi)利用4阶滞后求尼威-韦斯特标准误。wave2和wave3的r统计量如何?与通常OLS的统计量相比,你预计它会变大还是变小?
(vii)现在,求第(ii)部分中估计模型的普莱斯-温斯顿估计值。wave2和wave3是联合显著的吗?
第10题
(i)估计工业生产百分比变化(以年变化率来报告) pc ip, 的一个AR(3) 模型。证明二阶和三阶滞后在2.5%的显著性水平上是联合显著的。
(ii)在第(i) 部分估计的方程中增加pcspr的一阶滞后。它是统计显著的吗?就工业生产的增长与股票价格的变化之间的格兰杰因果关系而言,这个结果告诉了你什么?
(iii)重做第(ii)部分,并得到一个异方差-稳健的!统计量。这个稳健检验改变了你在第(ii)部分得到的结论吗?























